Concepts#
Architecture#
In vantage6, a client can pose a question to the server, which is then delivered as an algorithm to the node (Fig. 1). When the algorithm completes, the node sends the results back to the client via the server. An algorithm may be enabled to communicate directly with twin algorithms running on other nodes.
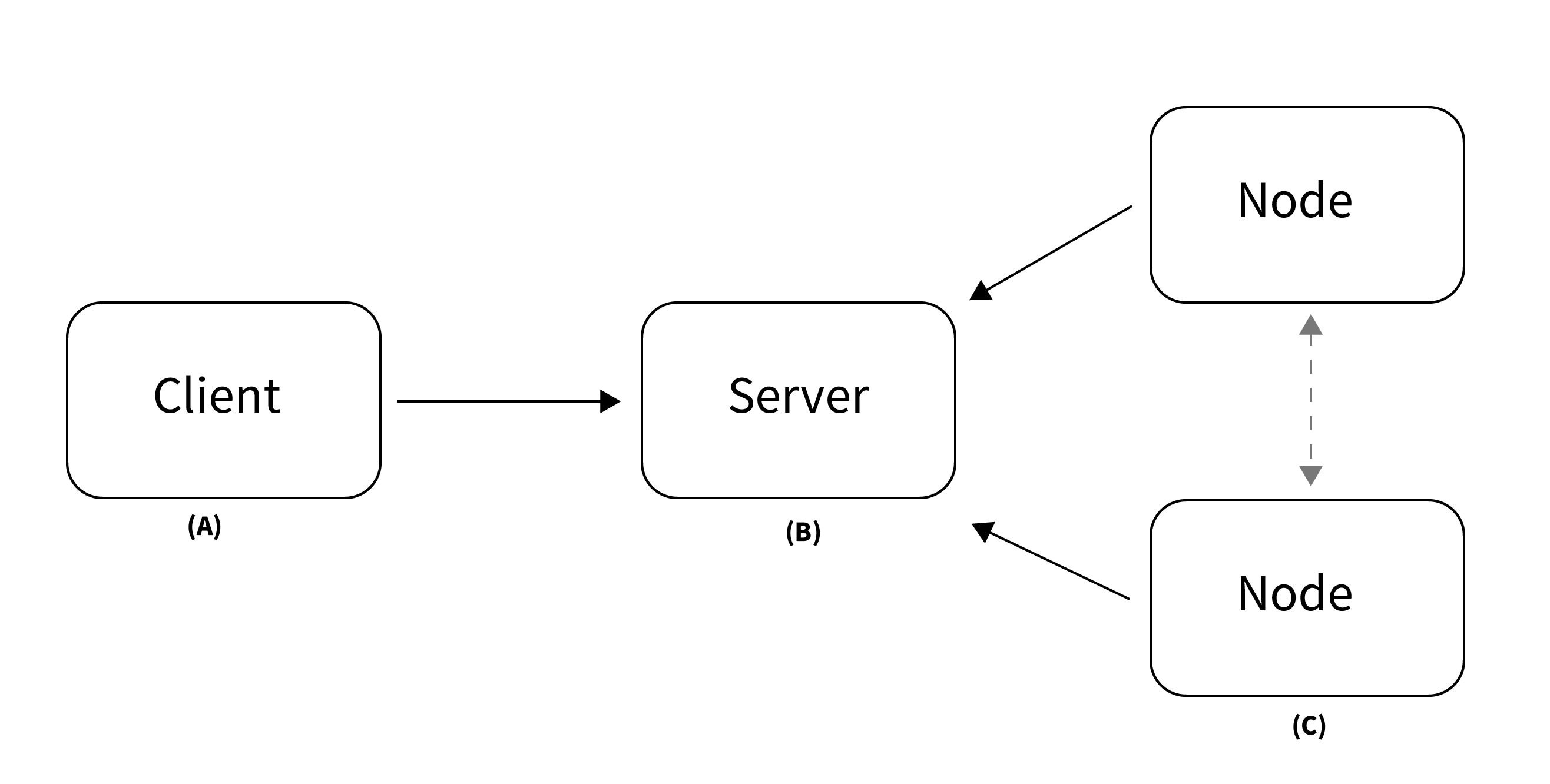
Fig. 1 Vantage6 has a client-server architecture. (A) The client is used by the researcher to create computation requests. It is also used to manage users, organizations and collaborations. (B) The server contains users, organizations, collaborations, tasks and their results. (C) The nodes have access to data and handle computation requests from the server.#
Conceptually, vantage6 consists of the following parts:
A (central) server that coordinates communication with clients and nodes. The server is in charge of processing tasks as well as handling administrative functions such as authentication and authorization.
One or more node(s) that have access to data and execute algorithms
Users (i.e. researchers or other applications) that request computations from the nodes via the client
Organizations that are interested in collaborating. Each user belongs to one of these organizations.
A Docker registry that functions as database of algorithms
On a technical level, vantage6 may be seen as a container orchestration tool for privacy preserving analyses. It deploys a network of containerized applications that together ensure insights can be exchanged without sharing record-level data.
Entities#
There are several entities in vantage6, such as users, organizations, tasks, etc. The following statements should help you understand their relationships.
A collaboration is a collection of one or more organizations.
For each collaboration, each participating organization needs a node to compute tasks.
Each organization can have users who can perform certain actions.
The permissions of the user are defined by the assigned rules.
It is possible to collect multiple rules into a role, which can also be assigned to a user.
Users can create tasks for one or more organizations within a collaboration.
A task should produce an algorithm run for each organization involved in the task. The results are part of such an algorithm run.
The following schema is a simplified version of the database:
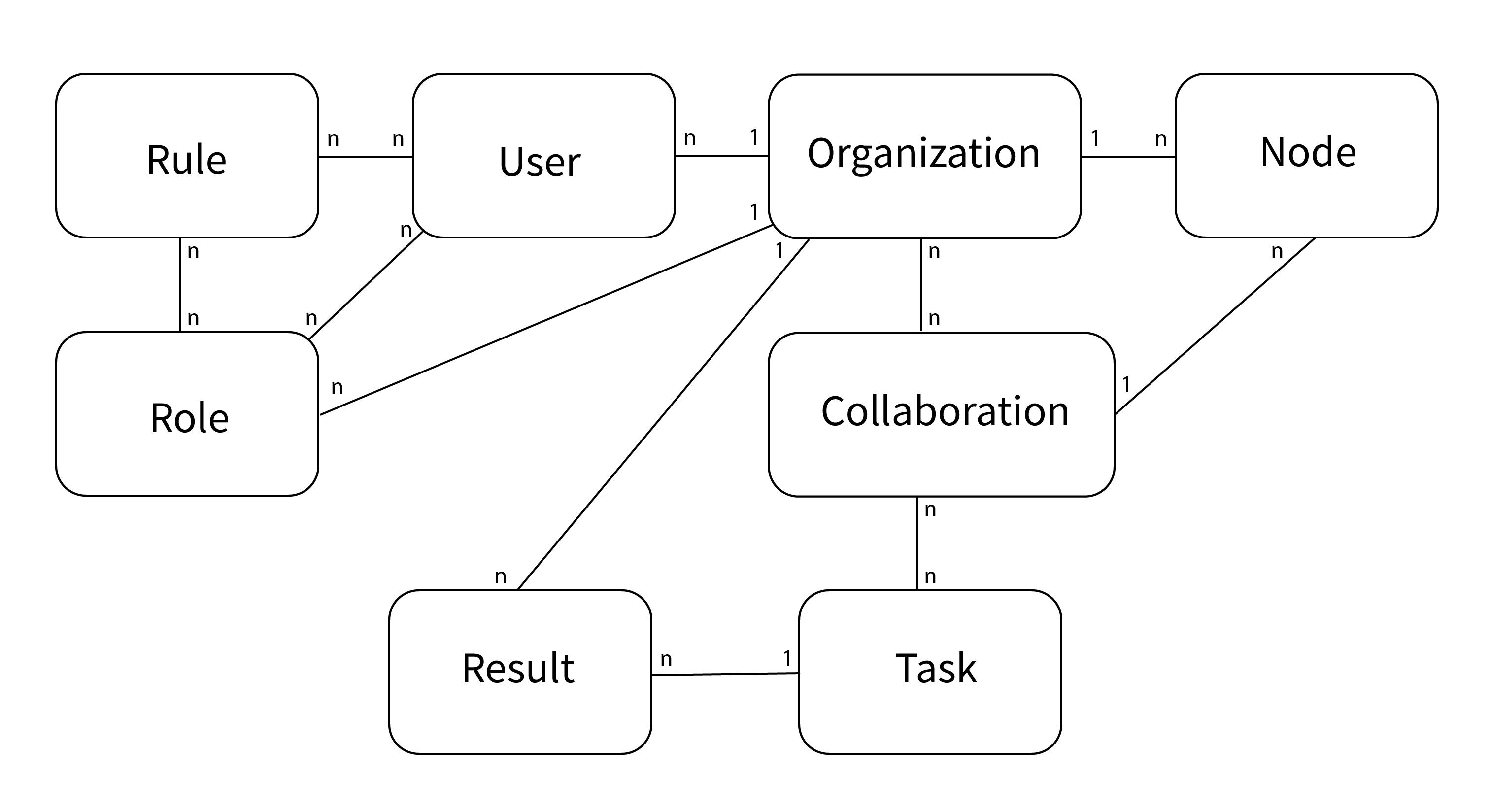
Fig. 2 Simplified database model#
Network Actors#
As we saw in Figure Fig. 1, vantage6 consists of a central server, a number of nodes and a client. This section explains in some more detail what these network actors are responsible for.
Server#
Note
When we refer to the server, this is not just the vantage6 server, but also other infrastructure components that the vantage6 server relies on.
The server is responsible for coordinating all communication in the vantage6 network. It consists of several components:
- vantage6 server
Contains the users, organizations, collaborations, tasks and their results. It handles authentication and authorization to the system and is the central point of contact for clients and nodes.
- Docker registry
Contains algorithms stored in Images which can be used by clients to request a computation. The node will retrieve the algorithm from this registry and execute it.
- VPN server (optionally)
If algorithms need to be able to engage in peer-to-peer communication, a VPN server can be set up to help them do so. This is usually the case when working with MPC, and is also often required for machine learning applications.
- RabbitMQ message queue (optionally)
The vantage6 server uses the socketIO protocol to communicate between server, nodes and clients. If there are multiple instances of the vantage6 server, it is important that the messages are communicated to all relevant actors, not just the ones that a certain server instance is connected to. RabbitMQ is therefore used to synchronize the messages between multiple vantage6 server instances.
Data Station#
- vantage6 node
The node is responsible for executing the algorithms on the local data. It protects the data by allowing only specified algorithms to be executed after verifying their origin. The node is responsible for picking up the task, executing the algorithm and sending the results back to the server. The node needs access to local data. For more details see the technical documentation of the node.
- database
The database may be in any format that the algorithms relevant to your use case support. The currently supported database types are listed here.
User or Application#
A user or application interacts with the vantage6 server. They can create tasks and retrieve their results, or manage entities at the server (i.e. creating or editing users, organizations and collaborations). This can be done using clients or via the user interface.
End to end encryption#
Encryption in vantage6 is handled at organization level. Whether encryption is used or not, is set at collaboration level. All the nodes in the collaboration need to agree on this setting. You can enable or disable encryption in the node configuration file, see the example in All configuration options.
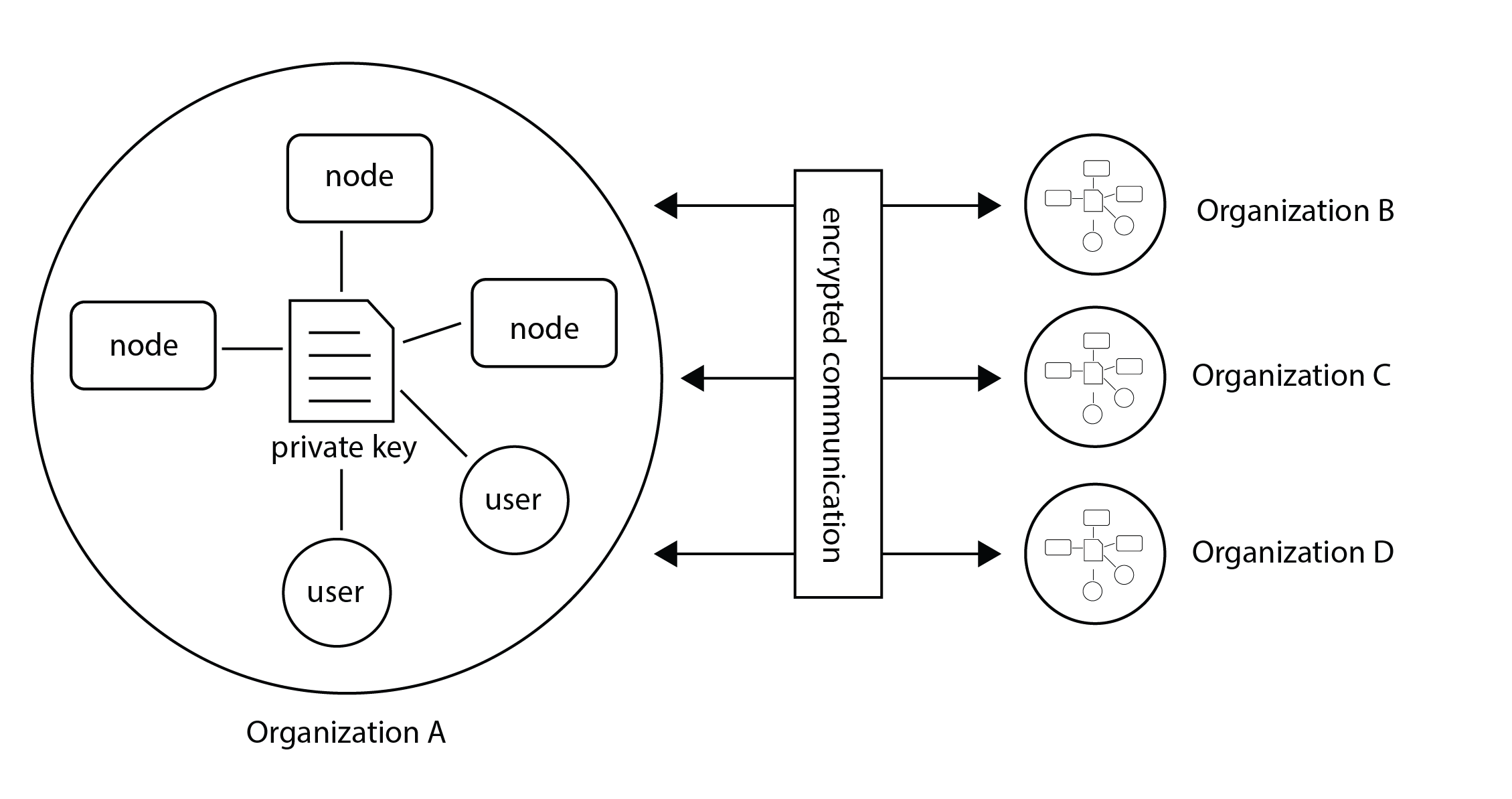
Fig. 3 Encryption takes place between organizations therefore all nodes and users from the a single organization should use the same private key.#
The encryption module encrypts data so that the server is unable to read communication between users and nodes. The only messages that go from one organization to another through the server are computation requests and their results. Only the algorithm input and output are encrypted. Other metadata (e.g. time started, finished, etc), can be read by the server.
The encryption module uses RSA keys. The public key is uploaded to the vantage6 server. Tasks and other users can use this public key (this is automatically handled by the python-client and R-client) to send messages to the other parties.
Note
The RSA key is used to create a shared secret which is used for encryption and decryption of the payload.
When the node starts, it checks that the public key stored at the server is derived from the local private key. If this is not the case, the node will replace the public key at the server.
Warning
If an organization has multiple nodes and/or users, they must use the same private key.
In case you want to generate a new private key, you can use the command
vnode create-private-key. If a key already exists at the local
system, the existing key is reused (unless you use the --force
flag). This way, it is easy to configure multiple nodes to use the same
key.
It is also possible to generate the key yourself and upload it by using the
endpoint https://SERVER[/api_path]/organization/<ID>.